Options du menu Rapports
- Rapports de codage (fonction principale de rapport)
- Comparaison de codage - pour les fichiers texte (compare 2 codeur⋅euses)
- Comparaison de codage par fichier - pour les fichiers texte (compare 2 codeur⋅euses)
- Nombre de codes par fichier/cas
- Fréquences des codes (totaux des codes appliqués)
- Résumé du fichier (détails d'un fichier et de ses segments codés)
- Résumé des codes (détails d'un code et des fichiers associés)
- Relations entre les codes - pour les fichiers texte (affiche la proximité, la correspondance exacte, les chevauchements, la distance entre les codes sélectionnés)
- Cooccurrence des codes - pour les fichiers texte (affiche le nombre de fois où un code est adjacent/chevauche/correspond exactement à un autre code)
- Correspondances exactes entre les codes - pour les fichiers texte (affiche le nombre de correspondances exactes entre les codes)
- Codes par segments de texte (affiche un tableau des noms de fichiers (lignes), du texte codé et des codes attribués - indiqués par 1).
- Afficher le graphique (créer ou afficher un graphique (carte) des objets et de leurs liens)
- Graphiques (afficher des graphiques statistiques et autres dans le navigateur web)
- Requêtes de base de données (requêtes de base de données, y compris les requêtes par défaut)
Rapports de codage
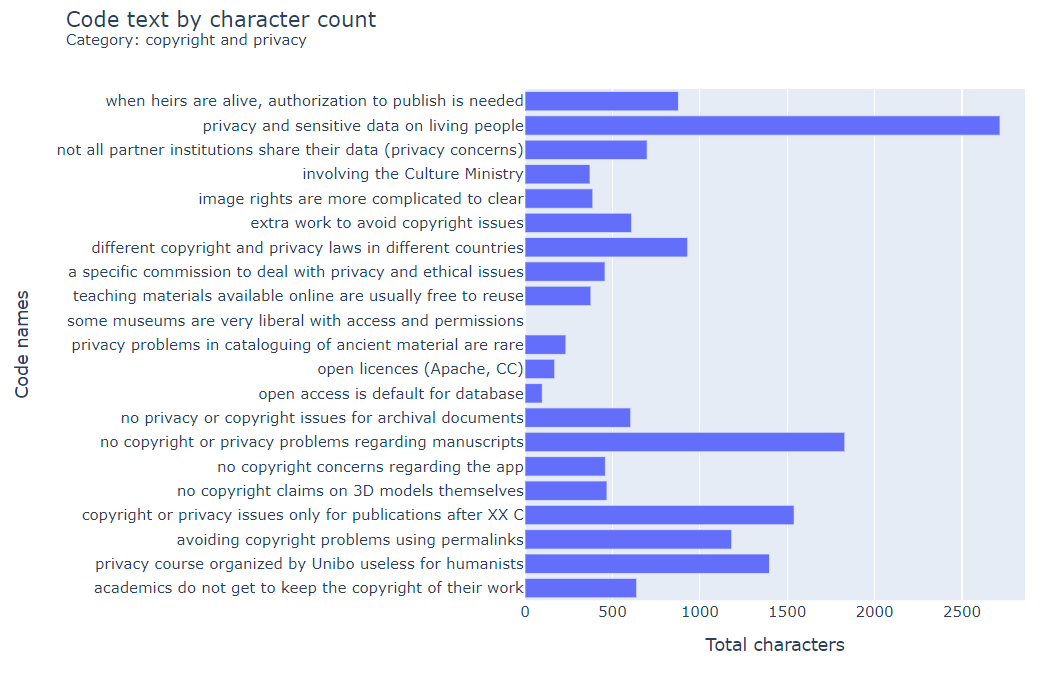
Ce rapport fournit une liste ou une matrice des données codées en fonction de vos sélections. Un ou plusieurs codes doivent être sélectionnés. Si une catégorie est sélectionnée, tous les codes de cette catégorie sont également sélectionnés. Plusieurs catégories peuvent être sélectionnées à l'aide de la souris et de la touche « Ctrl ».
Le bouton « Rechercher » (bouton « Lecture ») affiche les résultats.
Les résultats du codage peuvent être affinés à l'aide des boutons Sélection de fichiers, Sélection de cas ou Sélection d'attributs. Seuls les codages contenus dans les fichiers ou les cas sélectionnés seront présentés. Lorsque la sélection de cas est utilisée, la sélection de fichiers est ignorée. De même, lorsque la sélection de fichiers est utilisée, la sélection de cas est ignorée.
Si du texte est saisi dans le champ Rechercher du texte, seuls les codages contenant le texte correspondant seront présentés. Le texte recherché est également recherché dans les mémos des zones d'image codées et des segments audio/vidéo codés. La fonction de recherche de texte doit être utilisée en combinaison avec la sélection de fichiers, la sélection de cas ou la sélection d'attributs.
Textes, images et segments codés importants
Une case à cocher permet de sélectionner uniquement les codages importants. Cette fonction est utile pour trouver rapidement les exemples importants que vous pouvez utiliser dans un rapport écrit.
Sélection d'attributs dans les rapports
Le bouton Sélection d'attributs ouvre une fenêtre dans laquelle vous pouvez sélectionner des attributs pour les fichiers et les cas, par exemple : uniquement les fichiers d'entretien pour les personnes âgées de plus de 60 ans. De plus, les paramètres d'attributs peuvent être enregistrés, chargés et supprimés.
Matrice de codage
Si vous créez un rapport et sélectionnez l'une des options de matrice, le volet des résultats sera divisé en deux volets. Le volet gauche affiche les données codées sous forme de liste, tandis que le volet droit affiche une matrice composée de lignes et de colonnes. Les types de colonnes peuvent être des codes, des catégories ou des catégories de niveau supérieur.
Options de matrice : codes/catégories par fichier ou par cas. La matrice peut être transposée à l'aide de la case à cocher.
Les volets peuvent être élargis ou rétrécis en faisant glisser la souris sur la barre qui sépare chaque section.
Les rapports peuvent être exportés vers des fichiers texte, Open Document (ODT), HTML ou CSV.
Lorsque des cas sont sélectionnés, un autre volet s'affiche, présentant un tableau des cas (en lignes) et des catégories ou codes en colonnes
Cases à cocher
- Cochez cette case pour afficher uniquement les segments codés qui ont été marqués comme importants.
- Cochez cette case pour ajouter des statistiques récapitulatives au rapport.
- Cochez cette case pour afficher le contexte des segments de texte codés. Cela permet d'afficher les 100 à 300 caractères de texte environnants (paramètre défini dans les paramètres) afin de replacer la section codée dans son contexte dans les résultats. Le segment de texte codé est affiché en gras.
- Cochez cette case pour ajouter une référence au résultat codé. Cela s'applique si une référence a été importée et liée au fichier spécifique.
Autres fonctions
- Raccourci H. Appuyez sur h pour masquer ou afficher la section des commandes supérieures de la fenêtre.
Mémos
- Affichage des mémos. Une liste déroulante propose différentes options : ne pas inclure de mémos, inclure divers mémos ou afficher les annotations des fichiers texte sélectionnés.
Cliquez-droit sur un en-tête de code dans le rapport généré pour afficher d'autres options de menu : Afficher dans le contexte, désélectionner, modifier le code.
Exportation des rapports
Les rapports peuvent être exportés au format html, odt, txt, csv, xlsx.
txt est un fichier texte brut.
csv est un format de feuille de calcul texte brut.
xlsx est une feuille de calcul Microsoft Word contenant uniquement du texte.
odt est un format Open Document Text. Ce format peut être ouvert avec Microsoft Word ou LibreOffice Writer. Il contient du texte, des couleurs et des images. Par exemple, si vous avez des images codées.
iramuteq est une option d’export pour le texte, permettant d’importer le texte au sein du logiciel Iramuteq.
HTML est un format de navigateur web. Pour le texte brut, il n'y aura qu'un fichier html, par exemple coding_report.html. Si votre codage contient des images, des fichiers audio ou vidéo, il y aura un dossier supplémentaire, par exemple le dossier coding_report. Ce dossier contient les fichiers audio, vidéo et image nécessaires à l'affichage html. Pour transférer le fichier html à une autre personne ou le déplacer dans votre structure de dossiers, vous devez déplacer À LA FOIS le fichier html et le dossier associé, comme indiqué ci-dessous.display. Pour transférer le fichier HTML à une autre personne ou le déplacer dans votre structure de dossiers, vous devez déplacer À LA FOIS le fichier HTML et le dossier associé, comme indiqué ci-dessous.
Rapport de comparaison de codage
Cette option affiche les similitudes et les différences globales entre deux codeur⋅euses dans tous les fichiers texte. Sélectionnez deux codeur⋅euses et cliquez sur le bouton « Exécuter les comparaisons ». Les statistiques créées ici concernent uniquement le texte codé, et non les images ou les fichiers multimédias codés.
Pour chaque code :
Le pourcentage de concordance indique le degré de concordance entre les caractères textuels codés et non codés.
Les pourcentages A et B indiquent le degré de concordance entre les seuls caractères textuels codés, divisé par le nombre total de caractères dans le texte.
Le pourcentage « Ni A ni B » indique le total du texte non codé divisé par le nombre total de caractères dans le texte.
Le pourcentage de désaccord indique le pourcentage de tout le texte codé et non codé qui ne correspondait pas entre les codeur⋅euses. Il est égal à 100 moins le pourcentage de concordance.
Le pourcentage de concordance uniquement codé indique le pourcentage de tout le texte à double codage divisé par le texte à codage unique et double.
Le coefficient Kappa de Cohen est calculé à partir des informations disponibles sur Wikipédia.
Boutons permettant d'effectuer les comparaisons, d'effacer les codeur⋅euses sélectionnés, d'exporter vers Excel et d'ouvrir une fenêtre d'aide sur les statistiques.
Rapport de comparaison de codage par fichier
Cette option affiche les similitudes et les différences globales entre deux codeur⋅euses dans UN fichier sélectionné. Sélectionnez un fichier, un code et deux codeur⋅euses. Cliquez ensuite sur le bouton « Exécuter les comparaisons ». Les statistiques et les comparaisons pour les segments audio/vidéo codés sont en cours de développement. La concordance globale, la discordance et le coefficient Kappa de Cohen sont calculés pour le texte et les images. Un fichier image s'affiche dans une fenêtre séparée, montrant les sélections des deux codeur⋅euses dans des zones encadrées en jaune ou en bleu. Le texte en vert indique les endroits où les deux codeur⋅euses ont codé la même section de texte. Le survol de la souris fournit des informations supplémentaires.
Rapport de fréquence de codes
Cette fenêtre affiche tous les codes et catégories ainsi que la fréquence d'utilisation pour chaque codeur⋅euse. Les fréquences des codes peuvent être sélectionnées pour des fichiers spécifiques.
Rapport de relations de code
Cette boîte de dialogue affiche les relations entre deux codes ou plus. Elle ne peut être appliquée qu'aux fichiers texte. Sélectionnez deux codes ou plus, puis cliquez sur le bouton Calculer. Ce rapport peut être utile pour montrer la proximité ou les chevauchements entre les codes. Notez que d'autres rapports, tels que Code Co-occurrence et Code Text Exact Matches, font également cela. Ce rapport fournit de nombreux détails précis, tels que les positions des caractères de codage pour chaque code. Un fichier CSV peut être exporté.
Les relations sont les suivantes :
- Proximité : deux codes ne se chevauchent pas. La distance en nombre de caractères est indiquée.
- Chevauchement : deux codes se chevauchent partiellement. Les positions des caractères les plus basses et les plus élevées de la combinaison sont indiquées. L'union de la section qui se chevauche est indiquée en positions de caractères.
- Inclusion – Un code est inclus dans un autre code. Les positions minimale et maximale des caractères de la combinaison sont indiquées. L'union de la section qui se chevauche est indiquée en positions de caractères.
- Exact – Les deux codes correspondent dans leurs positions de début et de fin. Les positions minimale et maximale des caractères de la combinaison sont indiquées. L'union de la section qui se chevauche est indiquée en positions de caractères.
Des statistiques sommaires et des boîtes à moustaches peuvent être générées.
Rapport de co-occurences de codes
Ce rapport présente un tableau de noms de codes sur les axes x et y. Les cellules du tableau indiquent le nombre de cooccurrences de codes. Il s'agit des cas où deux codes se chevauchent ou sont directement contigus. Cliquez sur la cellule pour afficher les détails du codage du texte.
Les options disponibles sont les suivantes : sélectionner des fichiers texte spécifiques, sélectionner des fichiers par attributs, sélectionner des codes spécifiques ou sélectionner des catégories. Il existe une option d'exportation vers Excel.
Clickez sur une cellule pour voir les détails.
Dans la version 3.8 et les versions ultérieures, vous pouvez cliquer-droit de la souris sur une cellule contenant du texte codé par cooccurrence pour créer un nouveau code fusionné qui combine les deux codes qui se chevauchent.
Rapport récapitulatif du fichier
Cliquez sur un fichier pour obtenir un résumé de celui-ci. Il décrit les métadonnées multimédias, les caractères et la fréquence des mots. Attributs. Il résume le nombre de codes pour ce fichier. Pour les codages de texte, il résume la longueur moyenne du texte. Pour les codages d'images, il résume la surface moyenne en pixels. Pour les codages audio/vidéo, il résume la longueur moyenne des segments.
Les 100 mots les plus fréquents sont soumis à des mots vides, ce qui exclut les mots de remplissage courants tels que « a », « the », etc. Consultez la liste dans le dossier Examples. Vous pouvez remplacer cette liste en fournissant votre propre fichier texte de mots vides et en le plaçant dans le dossier .qualcoder.
Rapport récapitulatif du code
Cliquez sur un code pour obtenir un résumé de ce code. Les codeur⋅euses qui ont utilisé le code. Le nombre de codages dans les médias texte, image et audio/vidéo. Pour les codages texte, il résume la longueur moyenne du texte et les mots les plus courants. Pour les codages image, il résume la surface moyenne en pixels. Pour les codages audio/vidéo, il résume la longueur moyenne des segments.
Les 100 mots les plus fréquents sont soumis à des mots vides, ce qui exclut les mots de remplissage courants tels que « a », « the », etc. Consultez la liste dans le dossier Examples. Vous pouvez remplacer cette liste en fournissant votre propre fichier texte de mots vides et en le plaçant dans le dossier .qualcoder.
Rapport de codage par segments de texte
Ce rapport affiche des lignes de segments de texte codés et des colonnes indiquant les codes qui ont été appliqués. Pour certains utilisateurs, par exemple dans le domaine juridique, il est pratique de voir quels codes ont été appliqués au même segment de texte. Un fichier Excel peut être exporté.
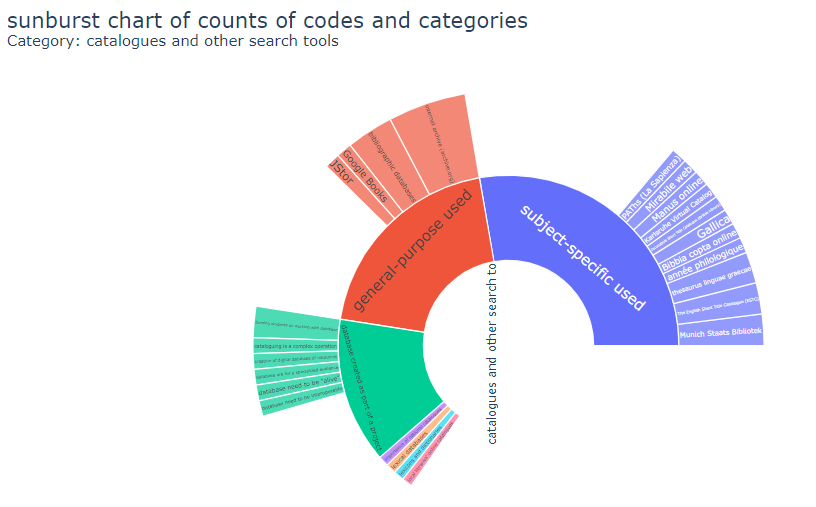
Graphiques
Différents types de graphiques et options de filtrage sont disponibles.
Il est possible de créer des graphiques circulaires, à barres, en rayons et Treemap.
À l'exception du nuage de mots, les graphiques s'affichent dans le navigateur Web par défaut. Si votre navigateur n'affiche pas votre graphique, commencez par changer votre navigateur Web par défaut pour un autre navigateur récent, par exemple Chrome, Edge ou Safari. Si vous avez désactivé javascript, les graphiques ne s'afficheront pas.
Il est possible de créer des cartes thermiques de fichiers ou de cas par rapport à des codes. Celles-ci sont limitées à 40 lignes et colonnes pour un rendu plus rapide et une meilleure visibilité.
Sélections de graphiques
Graphique à barres
Graphique en rayons
Cartes thermiques
des fichiers ou de cas par codes et affiche une carte thermique de la fréquence des codes.
Graphiques à barres empilées
des fichiers ou de cas par codes et affiche la fréquence des codes sous forme de graphiques à barre empilées.
Nuage de mots
Un nuage de mots est disponible avec différentes options pour la couleur d'arrière-plan, la couleur de premier plan ou la gamme de couleurs, la taille du rectangle, le nombre de mots (n-grammes) de 1 à 4 et le nombre maximum de mots à inclure. Le nombre maximum de mots est déterminé par la fréquence, du plus fréquent au moins fréquent, et la modification de cette option changera la densité ou la rareté du nuage de mots.
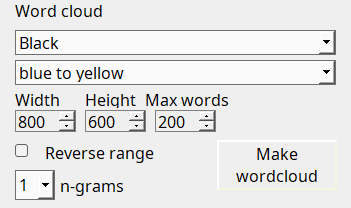
Il existe une liste de mots vides qui sont utilisés pour exclure les mots courants de l'affichage du nuage de mots (par exemple, an, a, the). Vous pouvez la remplacer en créant votre propre fichier stopwords.txt avec un mot par ligne. Ce fichier doit être placé dans le dossier .qualcoder. Par exemple, sous Windows :
« C:\Users\votrenom.qualcoder »
Les mots vides actuellement utilisés se trouvent dans le fichier stopwords.txt du dossier Examples.

Requêtes de base de données
Appliquez des instructions SQL pour interroger les données.
Cette fenêtre contient trois volets. Le volet supérieur sert à saisir les instructions SQL et le volet inférieur contient les résultats des requêtes. Le volet gauche contient les noms des tables et des champs. Double-cliquez sur un nom de champ pour l'ajouter à l'instruction SQL. Les résultats peuvent être exportés vers un fichier délimité. Si vous n'êtes pas familiarisé avec le langage SQL, soyez vigilant, car vous pourrez mettre à jour et supprimer les données, ainsi que sélectionner des données. Remarque : certains symboles Unicode ne sont pas convertis en texte brut et sont ignorés.
Plusieurs déclarations préparées sont répertoriées :
- Texte du cas
- Texte codé à l'aide d'une sélection d'attributs de cas (v3.6+)
- Codes fileid et texte codé
- Obtenir le tableau de codage - une implémentation d'une fonction RQDA qui renvoie le nom du code, le tableau, la longueur du texte et les positions de début et de fin du texte.
- Texte codé avec chaque cas
La plupart des champs du tableau sont des champs texte. Les champs suivants sont des entiers : anid, avid, attrid, caseid, catid, cid, fid, id, imid, jid, pos0, pos1, x1, y1, largeur, hauteur.
Cliquez-droit dans le tableau des résultats pour accéder aux options de filtrage.
Un clic droit dans la fenêtre SQL vous donne diverses options telles que tout sélectionner, copier, coller.
Au bas de la liste de gauche, vous pouvez voir : sql stocké et requêtes par défaut.
Le sql stocké correspond aux instructions sql que vous avez créées et stockées. Pour stocker une instruction sql, cliquez-droit sur le sql et choisissez « enregistrer la requête ».
Les requêtes par défaut, telles que celle illustrée dans l'image, sont des requêtes SQL prêtes à l'emploi permettant d'effectuer des extractions supplémentaires à partir de vos données. Elles sont accompagnées d'un commentaire « -- un commentaire » décrivant la fonction de chaque instruction.